
本項目以研究為目的,所有版權問題我們都是站在作者的一邊,以看盜版小說為目的的讀者們請自行面壁!
說了這么多,我們要做的就是把小說正文的內容從網頁上爬下來,我們的研究對象是全本小說網....再次聲明,不對任何版權負責....
一開始先做最基礎的內容,就是把某一章的內容抓取下來。
環境:Ubuntu, Python 2.7
基礎知識
這個程序涉及到的知識點有幾個,在這里列出來,不詳細講,有疑問的直接百度會有一堆的。
1.urllib2 模塊的 request 對像來設置 HTTP 請求,包括抓取的 url,和偽裝瀏覽器的代理。然后就是 urlopen 和 read 方法,都很好理解。
2.chardet 模塊,用于檢測網頁的編碼。在網頁上抓取數據很容易遇到亂碼的問題,為了判斷網頁是 gtk 編碼還是 utf-8 ,所以用 chardet 的 detect 函數進行檢測。在用 Windows 的同學可以在這里 http://download.csdn.net/detail/jcjc918/8231371 下載,解壓到 python 的 lib 目錄下就好。
3. decode 函數將字符串從某種編碼轉為 unicode 字符,而 encode 把 unicode 字符轉為指定編碼格式的字符串。
4. re 模塊正則表達式的應用。search 函數可以找到和正則表達式對應匹配的一項,而 replace 則是把匹配到的字符串替換。
思路分析:
我們選取的 url 是 http://www.quanben.com/xiaoshuo/0/910/59302.html,斗羅大陸的第一章。你可以查看網頁的源代碼,會發現只有一個 content 標簽包含了所有章節的內容,所以可以用正則把 content 的標簽匹配到,抓取下來。試著把這一部分內容打印出來,會發現很多
和 ,
要替換成換行符, 是網頁中的占位符,即空格,替換成空格就好。這樣一章的內容就很美觀的出來了。完整起見,同樣用正則把標題爬下來。
程序
# -*- coding: utf-8 -*-
import urllib2
import re
import chardet
class Book_Spider:
def __init__(self):
self.pages = []
# 抓取一個章節
def GetPage(self):
myUrl = "http://www.quanben.com/xiaoshuo/0/910/59302.html";
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = { 'User-Agent' : user_agent }
request = urllib2.Request(myUrl, headers = headers)
myResponse = urllib2.urlopen(request)
myPage = myResponse.read()
#先檢測網頁的字符編碼,最后統一轉為 utf-8
charset = chardet.detect(myPage)
charset = charset['encoding']
if charset == 'utf-8' or charset == 'UTF-8':
myPage = myPage
else:
myPage = myPage.decode('gb2312','ignore').encode('utf-8')
unicodePage = myPage.decode("utf-8")
try:
#抓取標題
my_title = re.search('(.*?)
',unicodePage,re.S)
my_title = my_title.group(1)
except:
print '標題 HTML 變化,請重新分析!'
return False
try:
#抓取章節內容
my_content = re.search('(.*?)","
")
my_content = my_content.replace(" "," ")
#用字典存儲一章的標題和內容
onePage = {'title':my_title,'content':my_content}
return onePage
# 用于加載章節
def LoadPage(self):
try:
# 獲取新的章節
myPage = self.GetPage()
if myPage == False:
print '抓取失敗!'
return False
self.pages.append(myPage)
except:
print '無法連接服務器!'
#顯示一章
def ShowPage(self,curPage):
print curPage['title']
print curPage['content']
def Start(self):
print u'開始閱讀......
'
#把這一頁加載進來
self.LoadPage()
# 如果self的pages數組中存有元素
if self.pages:
nowPage = self.pages[0]
self.ShowPage(nowPage)
#----------- 程序的入口處 -----------
print u"""
---------------------------------------
程序:閱讀呼叫轉移
版本:0.1
作者:angryrookie
日期:2014-07-05
語言:Python 2.7
功能:按下回車瀏覽章節
---------------------------------------
"""
print u'請按下回車:'
raw_input()
myBook = Book_Spider()
myBook.Start()
程序運行完在我這里可是很好看的,不信請看:^_^
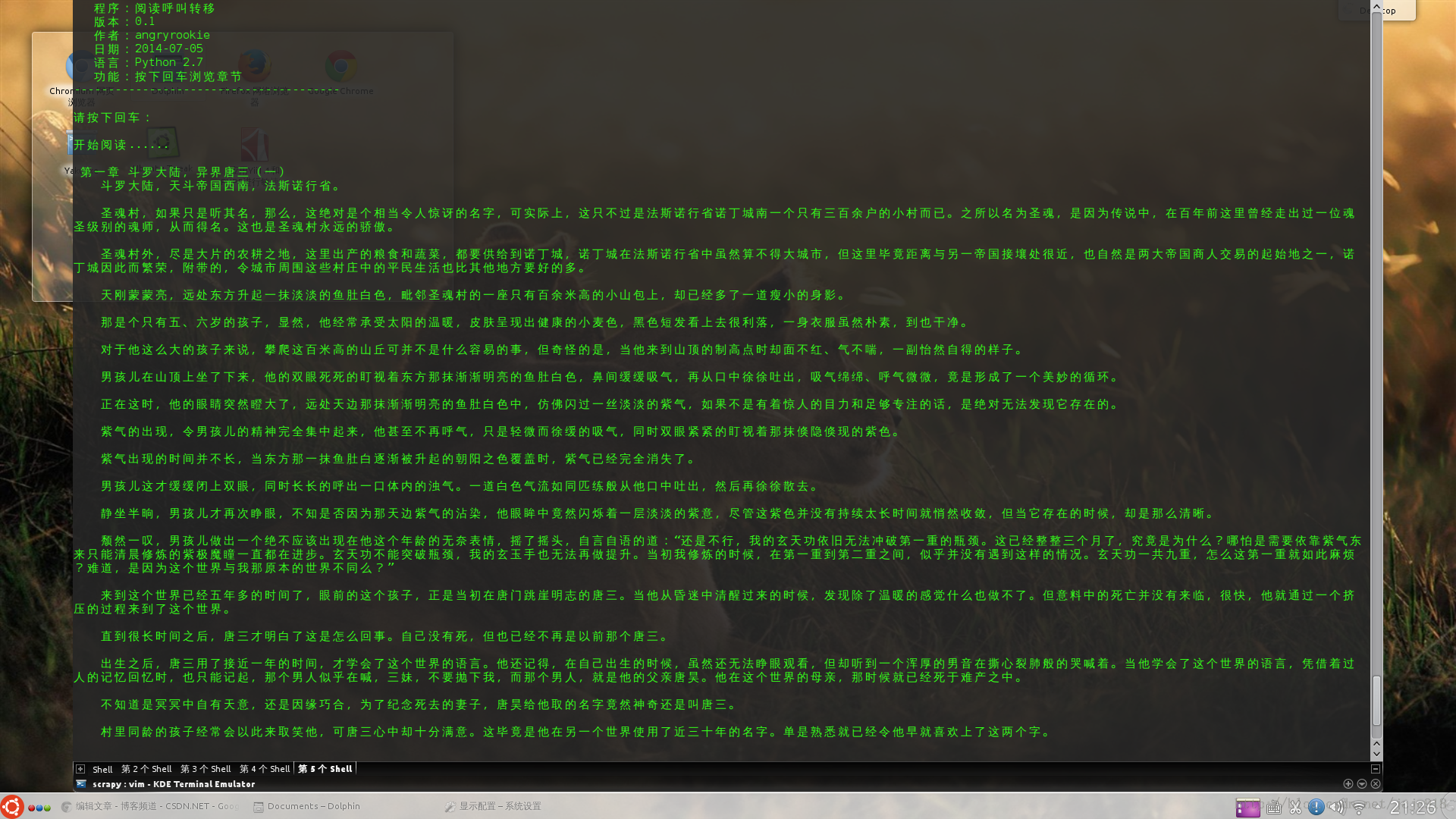
理所當然地,接下來我們要把整本小說都爬下來。首先,我們要把程序從原來的讀完一章就結束,改成讀完一章之后可以繼續進行下一章的閱讀。
注意到每個小說章節的網頁下面都有下一頁的鏈接。通過查看網頁源代碼,稍微整理一下( 不顯示了),我們可以看到這一部分的 HTML 是下面這種格式的:
上一頁 、返回目錄、下一頁都在一個 id 為 footlink 的 div 中,如果想要對每個鏈接進行匹配的話,會抓取到網頁上大量的其他鏈接,但是 footlink 的 div 只有一個啊!我們可以把這個 div 匹配到,抓下來,然后在這個抓下來的 div 里面再匹配 的鏈接,這時就只有三個了。只要取最后一個鏈接就是下一頁的 url 的,用這個 url 更新我們抓取的目標 url ,這樣就能一直抓到下一頁。用戶閱讀邏輯為每讀一個章節后,等待用戶輸入,如果是 quit 則退出程序,否則顯示下一章。
基礎知識:
上一篇的基礎知識加上 Python 的 thread 模塊.
源代碼:
# -*- coding: utf-8 -*-
import urllib2
import re
import thread
import chardet
class Book_Spider:
def __init__(self):
self.pages = []
self.page = 1
self.flag = True
self.url = "http://www.quanben.com/xiaoshuo/10/10412/2095096.html"
# 將抓取一個章節
def GetPage(self):
myUrl = self.url
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = { 'User-Agent' : user_agent }
req = urllib2.Request(myUrl, headers = headers)
myResponse = urllib2.urlopen(req)
myPage = myResponse.read()
charset = chardet.detect(myPage)
charset = charset['encoding']
if charset == 'utf-8' or charset == 'UTF-8':
myPage = myPage
else:
myPage = myPage.decode('gb2312','ignore').encode('utf-8')
unicodePage = myPage.decode("utf-8")
# 找出 id="content"的div標記
try:
#抓取標題
my_title = re.search('(.*?)
',unicodePage,re.S)
my_title = my_title.group(1)
except:
print '標題 HTML 變化,請重新分析!'
return False
try:
#抓取章節內容
my_content = re.search('(.*?)","
")
my_content = my_content.replace(" "," ")
#用字典存儲一章的標題和內容
onePage = {'title':my_title,'content':my_content}
try:
#找到頁面下方的連接區域
foot_link = re.search('(.*?)',unicodePage,re.S)
foot_link = foot_link.group(1)
#在連接的區域找下一頁的連接,根據網頁特點為第三個
nextUrl = re.findall(u'(.*?)',foot_link,re.S)
nextUrl = nextUrl[2][0]
# 更新下一次進行抓取的鏈接
self.url = nextUrl
except:
print "底部鏈接變化,請重新分析!"
return False
return onePage
# 用于加載章節
def LoadPage(self):
while self.flag:
if(len(self.pages) - self.page < 3):
try:
# 獲取新的頁面
myPage = self.GetPage()
if myPage == False:
print '抓取失敗!'
self.flag = False
self.pages.append(myPage)
except:
print '無法連接網頁!'
self.flag = False
#顯示一章
def ShowPage(self,curPage):
print curPage['title']
print curPage['content']
print "
"
user_input = raw_input("當前是第 %d 章,回車讀取下一章或者輸入 quit 退出:" % self.page)
if(user_input == 'quit'):
self.flag = False
print "
"
def Start(self):
print u'開始閱讀......
'
# 新建一個線程
thread.start_new_thread(self.LoadPage,())
# 如果self的page數組中存有元素
while self.flag:
if self.page <= len(self.pages):
nowPage = self.pages[self.page-1]
self.ShowPage(nowPage)
self.page += 1
print u"本次閱讀結束"
#----------- 程序的入口處 -----------
print u"""
---------------------------------------
程序:閱讀呼叫轉移
版本:0.2
作者:angryrookie
日期:2014-07-07
語言:Python 2.7
功能:按下回車瀏覽下一章節
---------------------------------------
"""
print u'請按下回車:'
raw_input(' ')
myBook = Book_Spider()
myBook.Start()
現在這么多小說閱讀器,我們只需要把我們要的小說抓取到本地的 txt 文件里就好了,然后自己選個閱讀器看,怎么整都看你了。
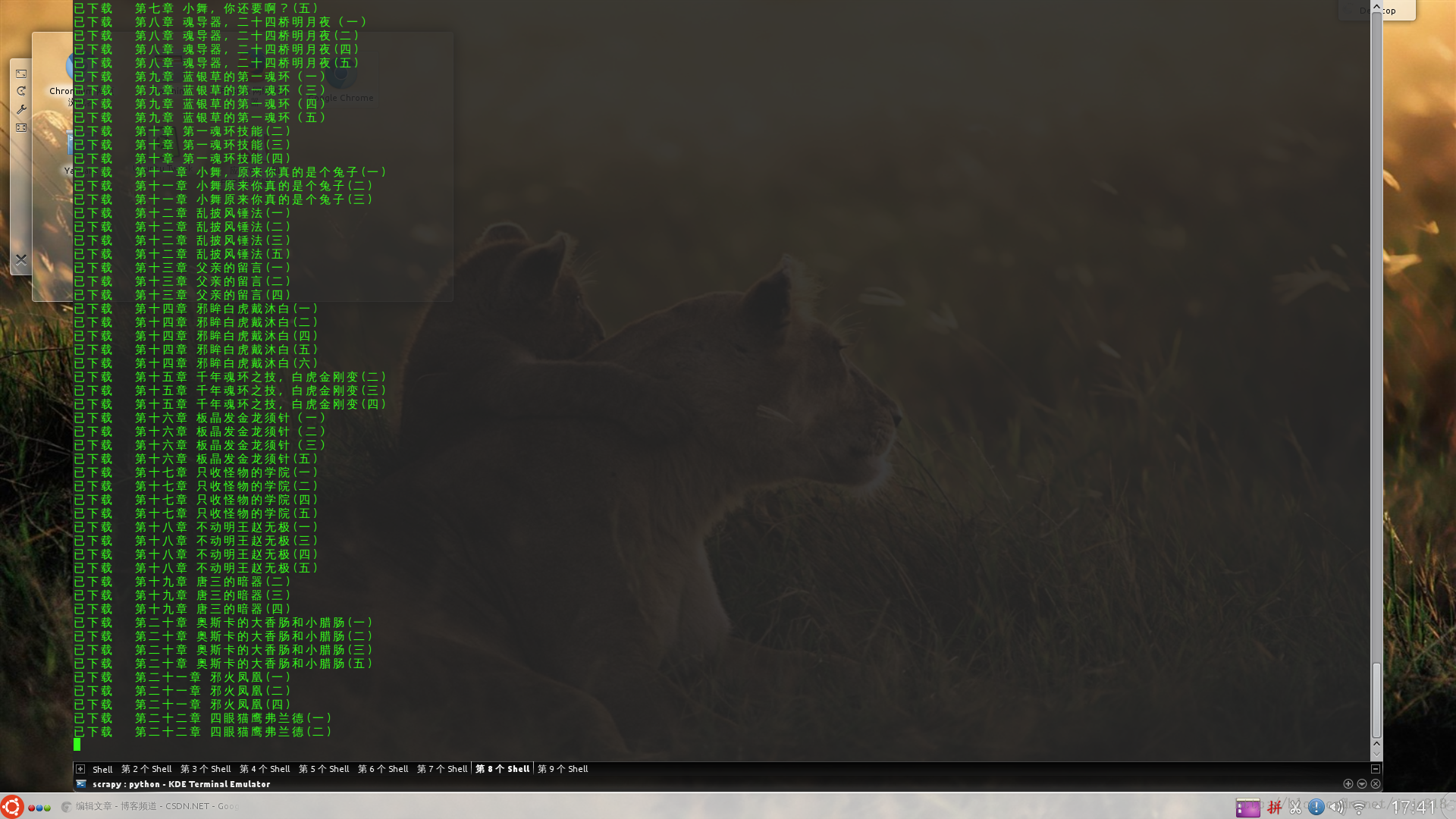
其實上個程序我們已經完成了大部分邏輯,我們接下來的改動只需要把抓取到每一章的時候不用顯示出來,而是存入 txt 文件之中。另外一個是程序是不斷地根據下一頁的 Url 進行抓取的,那么什么時候結束呢?注意當到達小說的最后一章時下一頁的鏈接是和返回目錄的鏈接是一樣的。所以我們抓取一個網頁的時候就把這兩個鏈接拿出來,只要出現兩個鏈接一樣的時候,就停止抓取。最后就是我們這個程序不需要多線程了,我們只要一個不斷在抓取小說頁面的線程就行了。
不過,小說章節多一點時候,等待完成的時間會有點久。目前就不考慮這么多了,基本功能完成就 OK....
基礎知識:前面的基礎知識 - 多線程知識 + 文件操作知識。
源代碼:
# -*- coding:utf-8 -*-
import urllib2
import urllib
import re
import thread
import chardet
class Book_Spider:
def __init__(self):
self.pages = []
self.page = 1
self.flag = True
self.url = "http://www.quanben.com/xiaoshuo/0/910/59302.html"
# 將抓取一個章節
def GetPage(self):
myUrl = self.url
user_agent = 'Mozilla/4.0 (compatible; MSIE 5.5; Windows NT)'
headers = { 'User-Agent' : user_agent }
req = urllib2.Request(myUrl, headers = headers)
myResponse = urllib2.urlopen(req)
myPage = myResponse.read()
charset = chardet.detect(myPage)
charset = charset['encoding']
if charset == 'utf-8' or charset == 'UTF-8':
myPage = myPage
else:
myPage = myPage.decode('gb2312','ignore').encode('utf-8')
unicodePage = myPage.decode("utf-8")
# 找出 id="content"的div標記
try:
#抓取標題
my_title = re.search('(.*?)
',unicodePage,re.S)
my_title = my_title.group(1)
except:
print '標題 HTML 變化,請重新分析!'
return False
try:
#抓取章節內容
my_content = re.search('(.*?)","
")
my_content = my_content.replace(" "," ")
#用字典存儲一章的標題和內容
onePage = {'title':my_title,'content':my_content}
try:
#找到頁面下方的連接區域
foot_link = re.search('(.*?)',unicodePage,re.S)
foot_link = foot_link.group(1)
#在連接的區域找下一頁的連接,根據網頁特點為第三個
nextUrl = re.findall(u'(.*?)',foot_link,re.S)
#目錄鏈接
dir_url = nextUrl[1][0]
nextUrl = nextUrl[2][0]
# 更新下一次進行抓取的鏈接
self.url = nextUrl
if(dir_url == nextUrl):
self.flag = False
return onePage
except:
print "底部鏈接變化,請重新分析!"
return False
# 用于加載章節
def downloadPage(self):
f_txt = open(u"斗羅大陸.txt",'w+')
while self.flag:
try:
# 獲取新的頁面
myPage = self.GetPage()
if myPage == False:
print '抓取失敗!'
self.flag = False
title = myPage['title'].encode('utf-8')
content = myPage['content'].encode('utf-8')
f_txt.write(title + '
')
f_txt.write(content)
f_txt.write('
')
print "已下載 ",myPage['title']
except:
print '無法連接服務器!'
self.flag = False
f_txt.close()
def Start(self):
print u'開始下載......
'
self.downloadPage()
print u"下載完成"
#----------- 程序的入口處 -----------
print u"""
---------------------------------------
程序:閱讀呼叫轉移
版本:0.3
作者:angryrookie
日期:2014-07-08
語言:Python 2.7
功能:按下回車開始下載
---------------------------------------
"""
print u'請按下回車:'
raw_input(' ')
myBook = Book_Spider()
myBook.Start()
聲明:本網頁內容旨在傳播知識,若有侵權等問題請及時與本網聯系,我們將在第一時間刪除處理。TEL:177 7030 7066 E-MAIL:11247931@qq.com
Copyright ? 2019-2025 51dongshi.com 版權所有
違法及侵權請聯系:TEL:177 7030 7066 E-MAIL:11247931@qq.com 本站由北京市萬商天勤律師事務所王興未律師提供法律服務


